Recruiting Infrastructure: 80K Records, One Pipeline
Scalable recruiting infrastructure: Cloud SQL, Cloud Run. 100+ data sources harvested into an 80K-record dataset at >90% accuracy.
Project Tags
100 Data Sources, No Single Source of Truth
Candidate data was everywhere and nowhere. Conference attendee lists in CSV files. GitHub profiles bookmarked in browsers. Codeforces rankings in spreadsheets. Olympiad results in PDFs. Over 100 data sources, each in its own format, none talking to the others.
Deduplication was manual. A single candidate might appear five times across three systems. There was no way to search, rank, or triage at scale. The recruiting team was spending more time wrangling data than evaluating talent.
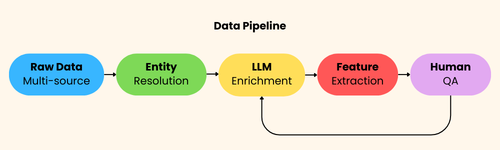
80,000 Records at 90%+ Accuracy - One Unified Pipeline
Built a scalable recruiting infrastructure: Cloud SQL for transactional data, Cloud Run for everything else. Integrated LinkedIn Recruiter RSC for seamless platform interop.
Python scrapers harvest 100+ data sources - conferences, Olympiads, GitHub, Codeforces - producing an 80K-record dataset at greater than 90% field-level accuracy. Now piloting LLM-assisted candidate triage via Anthropic’s Model Context Protocol for the next step: intelligent, automated first-pass review.