AI Candidate Screening: Signal-Based Evaluation at Scale
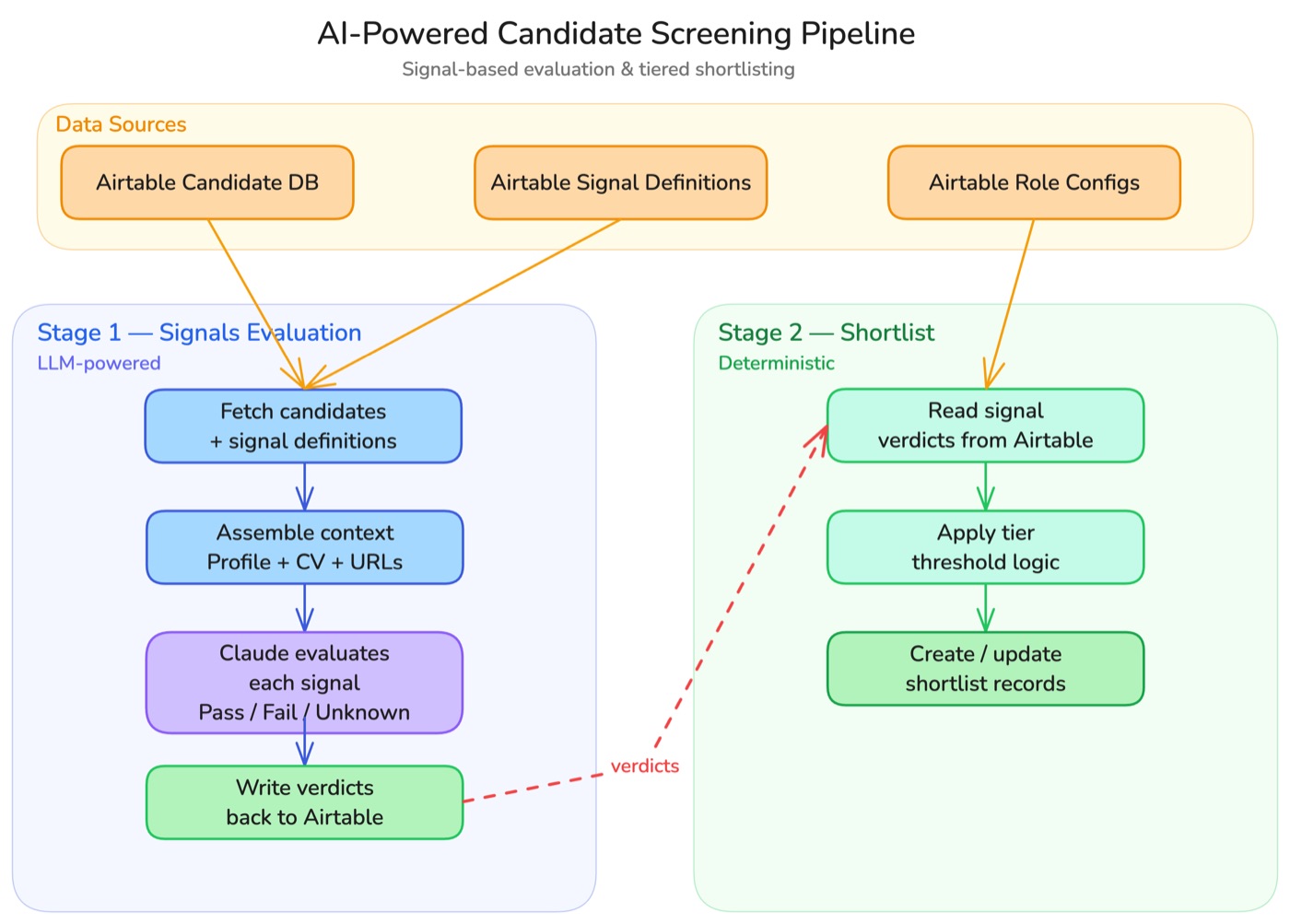
Automated two-stage screening pipeline: Claude evaluates candidates against configurable binary signals, then deterministic tier logic shortlists the top performers.
Project Tags
Likert Scales Don’t Force Real Decisions
We historically evaluated candidates using 1–5 Likert ratings on Airtable. The problem: reviewers gravitated toward average scores to avoid making difficult calls, or because the evidence wasn’t clear-cut. A candidate rated 3/5 on “technical depth” tells you almost nothing—it’s a hedge, not a signal.
The scores were also hard to compare across roles and organizations. What counts as a 4 for one reviewer is a 3 for another. Re-screening when requirements changed meant re-reading every profile and re-calibrating the same ambiguous scale.
Binary Signals: Pass, Fail, or Unknown—No Middle Ground
Replaced Likert scales with binary signal evaluation. Each candidate is scored against specific, testable variables—has_shipped_python_in_production, has_published_at_top_20_conference, has_completed_cs_phd—with three possible verdicts: pass, fail, or unknown. Claude evaluates each signal with evidence citations drawn from CVs, LinkedIn, GitHub, and personal websites.
Binary signals are definitive and actionable—no room for fence-sitting. General variables like has_completed_cs_phd work across roles and orgs, while role-specific ones can be added as needed. The result: a recruiter can scan a candidate’s signal profile and immediately see who to shortlist, without re-reading source material or second-guessing ambiguous ratings.